

프로젝트 개요
현재 프로젝트에서는 클라우드 VM 환경에서 모니터링 시스템을 구축하여, 모니터링 시스템의 전체 구조와 작동 원리에 대한 이해를 높이기 위한 학습 목적의 프로젝트이다.
해당 모니터링 시스템은 Prometheus, Grafana, Loki, Promtail, cAdvisor, Node Exporter로 구성된 스택을 기반으로 구축하였다. 이 시스템을 통해 인프라 상태를 실시간으로 파악할 수 있으며, 문제가 발생했을 때 원인을 신속하게 진단하고 대응할 수 있는 체계를 갖출 수 있다. 또한, 로그 데이터를 수집하고 시각화함으로써 운영 중 발생하는 이벤트나 에러를 보다 쉽게 분석할 수 있다는 장점이 있다.
아키텍처

주요 기술 스택
- Prometheus
- cAdvisor
- Node Exporter
- Grafana
- Loki
- Promtail
이번 프로젝트에서는 총 두 대의 VM을 사용하며, 한 대는 Master Server, 다른 한 대는 Target Server로 구성한다. Master Server는 중앙에서 여러 Target Server의 메트릭 및 로그 데이터를 수집하는 역할을 수행할 수 있다. 현제 프로젝트에서는 Target Server를 한대만 지정하여 사용하였다. (클라우드는 NCP를 활용하였다.)
Master Server는 Prometheus를 통해 각 Target Server에 설치된 cAdvisor와 Node Exporter로부터 메트릭을 Pull 방식으로 수집한다. 로그의 경우, Target Server에 설치된 Promtail이 수집한 로그를 Master Server의 Loki로 Push한다. 이렇게 수집된 메트릭과 로그는 Grafana를 통해 통합적으로 시각화된다.
시스템 배포는 Docker Compose를 활용하여 전체 모니터링 스택을 일관되게 구성하였다.
모니터링 범위는 다음과 같다.
- 운영체제(OS) 및 Docker 컨테이너의 메트릭 수집
- Docker Container에서 발생하는 로그 파일 수집
Github
https://github.com/rlaehdwn0105/Grafana-Promethus-Loki-Docker
모니터링 시스템 구성 요소 설명
Grafana
Grafana는 오픈 소스 기반의 모니터링 및 시각화 플랫폼이다. Prometheus와 같은 다양한 데이터 소스로부터 메트릭 데이터를 가져와 실시간으로 시각화할 수 있으며, 사용자 친화적인 인터페이스를 통해 대시보드를 직관적으로 구성할 수 있는 것이 특징이다.
또한 다양한 플러그인과 외부 시스템 연동을 지원하여 유연한 구성과 확장이 가능하며, 이를 통해 시스템 전반의 상태를 한눈에 파악하고 복잡한 데이터를 효과적으로 분석할 수 있다.
Loki
Loki는 Grafana Labs에서 개발한 오픈 소스 로그 수집 및 저장 시스템이다. Prometheus와 유사하게 라벨 기반으로 로그 메타데이터만 인덱싱하기 때문에 저장 공간을 효율적으로 사용할 수 있으며, 설정과 운영이 간단하고 비용적인 부담도 적다. 로그는 객체 스토리지(S3 등)에 저장되며, Grafana와 연동하여 시각화 및 분석이 가능하다. 또한 LogQL이라는 쿼리 언어를 제공하여 로그 데이터를 쉽게 검색하고 필터링할 수 있으며, 메트릭과 로그를 함께 분석할 수 있는 통합 환경을 구성할 수 있다.
Promtail
Promtail은 Loki와 함께 사용되는 로그 수집기로, 시스템이나 애플리케이션에서 생성되는 로그 파일을 읽고 라벨을 부여한 뒤 Loki로 전송하는 역할을 한다. 다양한 로그 소스 및 포맷을 지원하며, 수집된 로그는 중앙에서 관리되고 Grafana를 통해 시각적으로 분석할 수 있다. 이를 통해 분산된 환경에서도 로그를 일관되게 수집하고 모니터링할 수 있는 구조를 제공한다.
Prometheus
Prometheus는 오픈 소스 시스템 모니터링 및 경고 툴킷으로, 시계열 데이터베이스로서의 역할을 한다. Prometheus는 주로 메트릭 데이터를 수집하고 저장하는 데 사용되며, 이를 통해 시스템의 성능, 애플리케이션 상태 등을 모니터링할 수 있다. 또한, Prometheus는 쿼리 언어인 PromQL을 제공하여 복잡한 쿼리를 실행하고 데이터 분석을 할 수 있다. 알림 기능을 통해 특정 조건이 충족되면 경고를 보내주는 기능도 있어, 실시간으로 시스템의 문제를 감지하고 대응할 수 있다.
cAdvisor
cAdvisor는 컨테이너 자원 모니터링을 위한 도구로, Docker와 같은 컨테이너 런타임과 통합되어 컨테이너의 CPU, 메모리, 디스크 I/O 등의 자원 사용량을 실시간으로 수집한다. 수집된 데이터는 Prometheus와 연동되어 시각화 및 성능 분석에 활용되며, 컨테이너 기반 애플리케이션의 운영 상태를 효과적으로 관리할 수 있는 구조를 제공한다.
Node Exporter
Node Exporter는 서버의 하드웨어 및 OS 수준 메트릭을 수집하여 Prometheus에 전달하는 역할을 한다. 수집되는 데이터에는 CPU 사용률, 메모리 사용량, 디스크 공간 등의 정보가 포함되며, 이를 통해 서버 상태를 지속적으로 모니터링하고 리소스 사용을 효율적으로 관리할 수 있다.
Prometheus와 Loki의 데이터 수집 차이
Prometheus는 pull 방식을 사용하여 데이터를 수집한다. 서버가 주기적으로 대상 시스템의 메트릭 엔드포인트에 접근해 데이터를 직접 가져오는 구조이다. Node Exporter나 cAdvisor와 같은 exporter들이 데이터를 제공하고, Prometheus가 이를 스크래핑하는 방식이다.
반면 Loki는 push 방식을 사용한다. 로그 수집기(Promtail, Fluentd, Logstash 등)가 시스템 로그를 읽고 라벨을 붙여 Loki로 전송한다. 로그가 발생하는 즉시 수집기가 직접 전달하기 때문에 실시간 로그 수집이 가능하다.
Master Server
마스터 서버의 현재 파일의 구조는 다음과 같다.
├── docker-compose.yml
├── grafana
│ ├── grafana.ini
│ └── provisioning
│ ├── dashboards
│ │ ├── cadvisor-exporter-dashboard.json
│ │ ├── dashboard.yml
│ │ └── node-dashboard.json
│ └── datasources
│ └── datasource.yml
├── loki
│ └── loki-config.yml
├── prometheus
│ └── prometheus.yml
└── promtail
└── promtail-config.ymldocker-compose.yml
version: "3.8"
networks:
monitor-net:
driver: bridge
volumes:
prometheus_data: {}
grafana_data: {}
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus/:/etc/prometheus/
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
- '--web.enable-lifecycle'
- '--web.enable-admin-api'
ports:
- "9090:9090"
restart: unless-stopped
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
grafana:
image: grafana/grafana:latest
container_name: grafana
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning/:/etc/grafana/provisioning/
ports:
- "3000:3000"
restart: unless-stopped
networks:
- monitor-net
depends_on:
- prometheus
labels:
org.label-schema.group: "monitoring"
nodeexporter:
image: prom/node-exporter:latest
container_name: nodeexporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- "9100:9100"
restart: unless-stopped
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
privileged: true
devices:
- /dev/kmsg:/dev/kmsg
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
command:
- '--port=9101'
ports:
- "9101:9101"
restart: unless-stopped
networks:
- monitor-net
depends_on:
- prometheus
labels:
org.label-schema.group: "monitoring"
loki:
image: grafana/loki:latest
container_name: loki
ports:
- "3100:3100"
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
restart: unless-stopped
volumes:
- ./loki/loki-config.yml:/etc/loki/loki-config.yml
command:
- -config.file=/etc/loki/loki-config.yml
promtail:
image: grafana/promtail:latest
container_name: promtail
ports:
- "9080:9080"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./promtail/promtail-config.yml:/etc/promtail/promtail-config.yml
command:
- -config.file=/etc/promtail/promtail-config.yml
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
restart: unless-stopped
depends_on:
- loki본 Monitoring Stack은 설정 파일과 데이터를 모두 컨테이너 외부에서 관리하도록 구성하였다. Prometheus의 prometheus.yml, Loki의 loki-config.yml, Promtail의 promtail-config.yml 등 주요 설정 파일은 로컬 디렉토리에서 직접 마운트하고, prometheus_data, grafana_data와 같은 Docker 볼륨을 통해 수집된 메트릭 데이터 및 사용자 설정 정보를 외부에 저장함으로써, 컨테이너가 재시작되거나 재배포되는 경우에도 기존의 설정과 데이터가 손실되지 않도록 하였다.
또한, 모든 컨테이너는 monitor-net이라는 별도의 브리지 네트워크를 통해 내부적으로 통신하도록 구성하였다. 이를 통해 모니터링 서비스 간의 네트워크 트래픽이 외부 네트워크나 웹 서비스와 겹치지 않도록 분리되며, 각 서비스를 독립적으로 구성하고 관리할 수 있다.
Grafana 설정
dashboard.yml 파일은 Grafana가 어떤 JSON 대시보드 파일을 자동으로 로드할지 지정하는 설정 파일이며, datasource.yml은 Prometheus와 같은 외부 데이터 소스를 Grafana에 사전 등록하는 역할을 한다. 본 프로젝트에서는 node-exporter와 cAdvisor에 대한 대시보드를 미리 구성하고 컨테이너가 시작될 때 자동으로 적용되도록 설정하였다.대시보드는 Grafana Labs의 공식 템플릿이나 커뮤니티에서 공유되는 JSON 대시보드를 가져와 프로젝트 목적에 맞게 커스터마이징하여 사용하였다.
dashboard.yml
apiVersion: 1
providers:
- name: 'Prometheus'
orgId: 1
folder: ''
type: file
disableDeletion: false
editable: true
allowUiUpdates: true
options:
path: /etc/grafana/provisioning/dashboards
Grafana가 /etc/grafana/provisioning/dashboards 경로에 있는 대시보드 JSON 파일들을 자동으로 불러오고, 웹 UI를 통해 수정 및 삭제가 가능하도록 구성한 것이다.
datasource.yml
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus:9090
- name: Loki
type: loki
access: proxy
orgId: 1
url: http://loki:3100
basicAuth: false
isDefault: true
version: 1
editable: false현재 Grafana는 Prometheus와 Loki를 데이터 소스로 설정하고 있으며, 해당 설정 파일을 통해 각각의 메트릭(http://prometheus:9090)과 로그(http://loki:3100) 데이터에 proxy 방식으로 접근할 수 있도록 구성되어 있다. 이를 통해 Grafana는 두 데이터 소스를 기반으로 메트릭과 로그를 통합적으로 시각화할 수 있으며, URL, 인증 정보, 기본 데이터 소스 여부 등의 세부 설정도 함께 정의되어 있다.
grafana.ini
[paths]
provisioning = /etc/grafana/provisioning
[security]
admin_user = admin
admin_password = admin
[users]
default_theme = darkGrafana의 기본 설정을 정의한 것으로, 대시보드와 데이터 소스 등의 프로비저닝 경로를 /etc/grafana/provisioning으로 지정하고, 초기 관리자 계정의 아이디와 비밀번호를 각각 admin으로 설정하였다. 또한 사용자 인터페이스의 기본 테마를 다크 모드로 지정하였다.
prometheus 설정
prometheus.yml
global:
scrape_interval: 5s
scrape_timeout: 2s
evaluation_interval: 5s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: [ 'prometheus:9090' ]
- job_name: 'node-exporter'
static_configs:
- targets: [ 'loaclhost ip:9100' ]
labels:
hostname: "dj-master-server"
- targets: [ 'localhost ip:9100' ]
labels:
hostname: "dj-server1"
- job_name: 'cadvisor'
static_configs:
- targets:
- 'loaclhost ip1:9101'
- targets:
- 'localhost ip2:9101'Prometheus는 pull 기반의 수집 모델을 사용하기 때문에, cAdvisor와 node-exporter를 각 대상 서버에서 Docker 컨테이너로 실행시키고, 마스터 서버에서는 prometheus.yml 파일을 통해 해당 서버들로부터 메트릭 데이터를 주기적으로 수집하도록 구성하였다. 각 타겟 서버는 scrape_configs 항목에 정의되어 있으며, Prometheus는 이를 통해 메트릭을 가져온다. 또한, 레이블(labels) 기능을 활용하여 각 서버에 hostname 값을 부여함으로써 수집된 데이터를 식별하고 관리하기 쉽도록 하였다.
Loki 설정
loki-config.yml
auth_enabled: false
server:
http_listen_port: 3100
grpc_listen_port: 9096
common:
instance_addr: 0.0.0.0
path_prefix: /tmp/loki
storage:
filesystem:
chunks_directory: /tmp/loki/chunks
rules_directory: /tmp/loki/rules
replication_factor: 1
ring:
kvstore:
store: inmemory
query_range:
results_cache:
cache:
embedded_cache:
enabled: true
max_size_mb: 100
schema_config:
configs:
- from: 2020-10-24
store: tsdb
object_store: filesystem
schema: v12
index:
prefix: index_
period: 24h
storage_config:
filesystem:
directory: /tmp/loki/storage
limits_config:
enforce_metric_name: falseLoki는 Prometheus와 달리 Push 기반 로그 수집 방식을 사용하며, Promtail과 같은 에이전트로부터 로그를 전달받아 처리한다. 로그 데이터는 로컬 파일 시스템(/tmp/loki)에 저장되도록 구성하였다. 청크 데이터, 룰 파일, 인덱스는 각각 별도의 디렉터리에 분리되어 관리된다. 실제 운영 환경에서는 S3와 같은 외부 객체 스토리지를 사용하는 것이 일반적이나, 현재는 테스트 목적이므로 로컬 파일 시스템을 활용하였다. 또한 쿼리 성능 향상을 위해 embedded_cache를 활성화하여 최대 100MB까지 결과 데이터를 메모리에 캐시하도록 설정하였다.
promtail-config.yml
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://loki:3100/loki/api/v1/push
scrape_configs:
- job_name: docker
docker_sd_configs:
- host: unix:///var/run/docker.sock
refresh_interval: 10s
relabel_configs:
- source_labels: ['__meta_docker_container_name']
target_label: 'container_name'
- source_labels: ['__meta_docker_container_label_logging_jobname']
target_label: 'job'
- source_labels: ['__meta_docker_container_label_logging_level']
target_label: 'level'
- source_labels: ['__meta_docker_container_id']
target_label: 'container_id'
pipeline_stages:
- json:
expressions:
message: message
level: level
- multiline:
firstline: ^\d{4}-\d{2}-\d{2} \d{1,2}:\d{2}:\d{2}
max_wait_time: 1sPromtail이 Docker 소켓을 통해 실행 중인 컨테이너 로그를 자동으로 탐지하고 수집한 뒤, 이를 단계적으로 처리하여 Loki로 전송하도록 구성되어 있다. 먼저 docker_sd_configs를 통해 모든 컨테이너를 주기적으로 탐색하며, relabel_configs 항목에서는 컨테이너 이름, ID, 사용자 정의 라벨 등의 메타데이터를 추출하여 로그에 라벨로 부여한다. 이 라벨은 Grafana에서 로그를 필터링하거나 그룹화할 때 사용된다.
이후 로그는 pipeline_stages를 거쳐 처리된다. 먼저 json 스테이지에서 로그 내용을 JSON 형식으로 파싱하여 message, level 등의 필드를 추출하고, multiline 스테이지에서는 시간 형식을 기준으로 여러 줄로 나뉜 로그를 하나의 이벤트로 병합한다. 마지막으로, 가공된 로그는 clients 항목에 지정된 Loki 서버(http://loki:3100)로 푸시된다.
Target Server
다음은 타겟서버에서의 파일구조이다.
├── docker-compose.yml
└── promtail
└── promtail-config.ymldocker-compose.yml
version: "3.8"
networks:
monitor-net:
driver: bridge
services:
nodeexporter:
image: prom/node-exporter:latest
container_name: nodeexporter
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.rootfs=/rootfs'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.ignored-mount-points=^/(sys|proc|dev|host|etc)($$|/)'
ports:
- "9100:9100"
restart: unless-stopped
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
privileged: true
devices:
- /dev/kmsg:/dev/kmsg
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
command:
- '--port=9101'
ports:
- "9101:9101"
restart: unless-stopped
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
promtail:
image: grafana/promtail:latest
container_name: promtail
ports:
- "9080:9080"
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./promtail/promtail-config.yml:/etc/promtail/promtail-config.yml
command:
- -config.file=/etc/promtail/promtail-config.yml
networks:
- monitor-net
labels:
org.label-schema.group: "monitoring"
restart: unless-stopped해당 서버는 타겟 서버이므로 Grafana, Loki, Prometheus는 설치하지 않고, 메트릭 수집을 위한 node-exporter와 cAdvisor, 로그 수집을 위한 Promtail만 설정하였다. 상세 설명은 마스터 서버와 같기 때문에 생략하도록 하겠다.
Promtail 설정
promtail-config.yml
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://master server ip :3100/loki/api/v1/push
scrape_configs:
- job_name: docker
docker_sd_configs:
- host: unix:///var/run/docker.sock
refresh_interval: 10s
relabel_configs:
- source_labels: ['__meta_docker_container_name']
target_label: 'container_name'
- source_labels: ['__meta_docker_container_label_logging_jobname']
target_label: 'job'
- source_labels: ['__meta_docker_container_label_logging_level']
target_label: 'level'
- source_labels: ['__meta_docker_container_id']
target_label: 'container_id'
pipeline_stages:
- json:
expressions:
message: message
level: level
- multiline:
firstline: ^\d{4}-\d{2}-\d{2} \d{1,2}:\d{2}:\d{2}
max_wait_time: 1s마스터 서버와 같은 설정 파일에서 clients 항목의 URL에 마스터 서버의 IP만 입력해주면 된다. 이제 모든 설정이 완료되었으므로, docker compose up -d 명령어로 컨테이너를 실행한 후 Grafana 대시보드를 통해 수집된 로그와 메트릭을 확인해보면 된다.
Grafana확인

Grafana 대시보드에 접속하려면 브라우저에서 localhost:3000으로 접속한다. 로그인 계정은 grafana.ini 파일에서 아이디와 비밀번호를 모두 admin으로 설정해두었기 때문에, 해당 값을 입력하면 바로 접속할 수 있다.
DataSource 확인

Datasource에 Loki와 Prometheus 정보가 등록된 모습을 확인할 수 있다.
Dashboard 확인
cAdvisor와 node-exporter를 기반으로 한 메트릭 대시보드는 정상적으로 구축되어 시스템 리소스를 시각적으로 확인할 수 있다. Loki의 경우에는 에러 로그만 간단히 확인할 예정이므로, 이를 위한 대시보드는 별도로 커스터마이징하여 구성할 계획이다.
Container Metric Dashboard
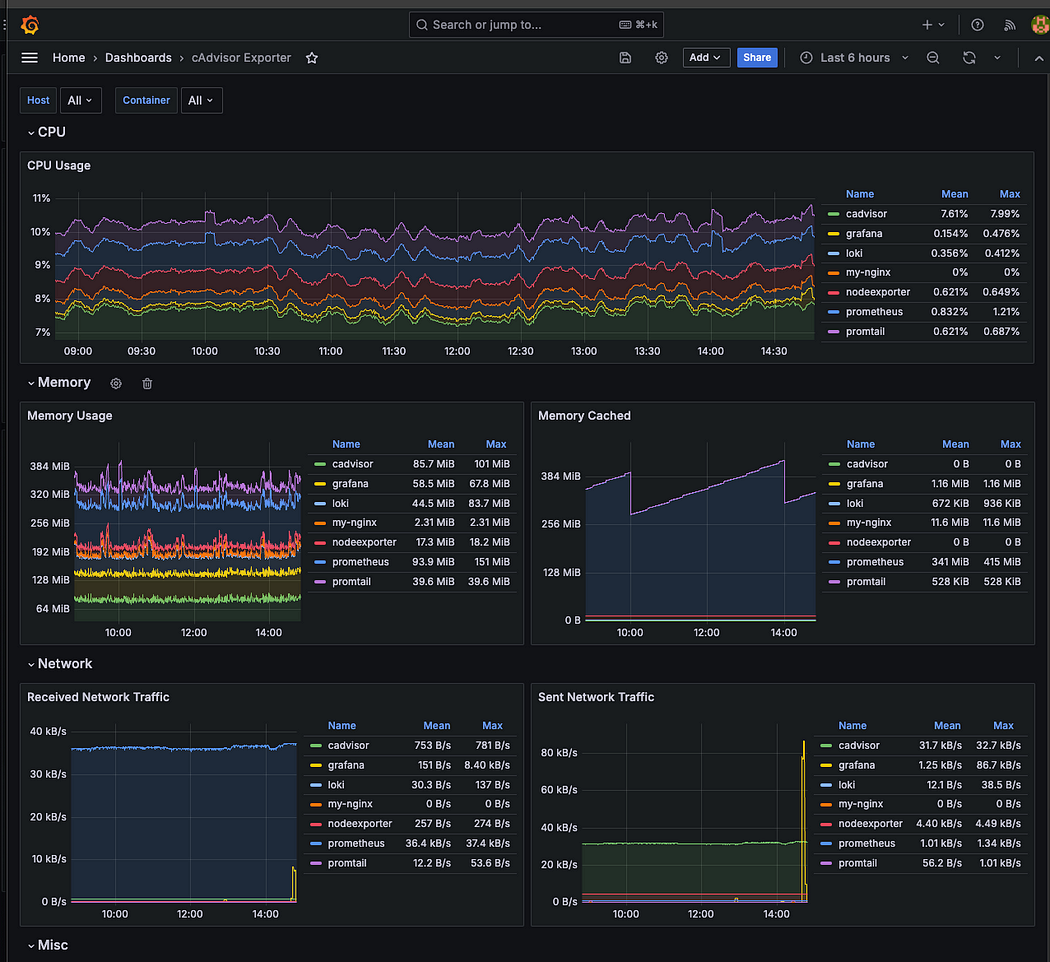
현재 실행 중인 컨테이너들(cAdvisor, Grafana, Loki, Node Exporter 등)의 CPU, 메모리, 캐시, 네트워크 트래픽 사용량을 Grafana 대시보드를 통해 직관적으로 모니터링할 수 있도록 구성하였다. 현재는 모든 호스트의 데이터를 한 화면에 표시하고 있지만, 라벨을 통해 각 호스트를 구분해두었기 때문에, 필요에 따라 호스트별 리소스 사용 현황을 개별적으로 확인할 수 있다.
Node Resource Monitoring Dashboard
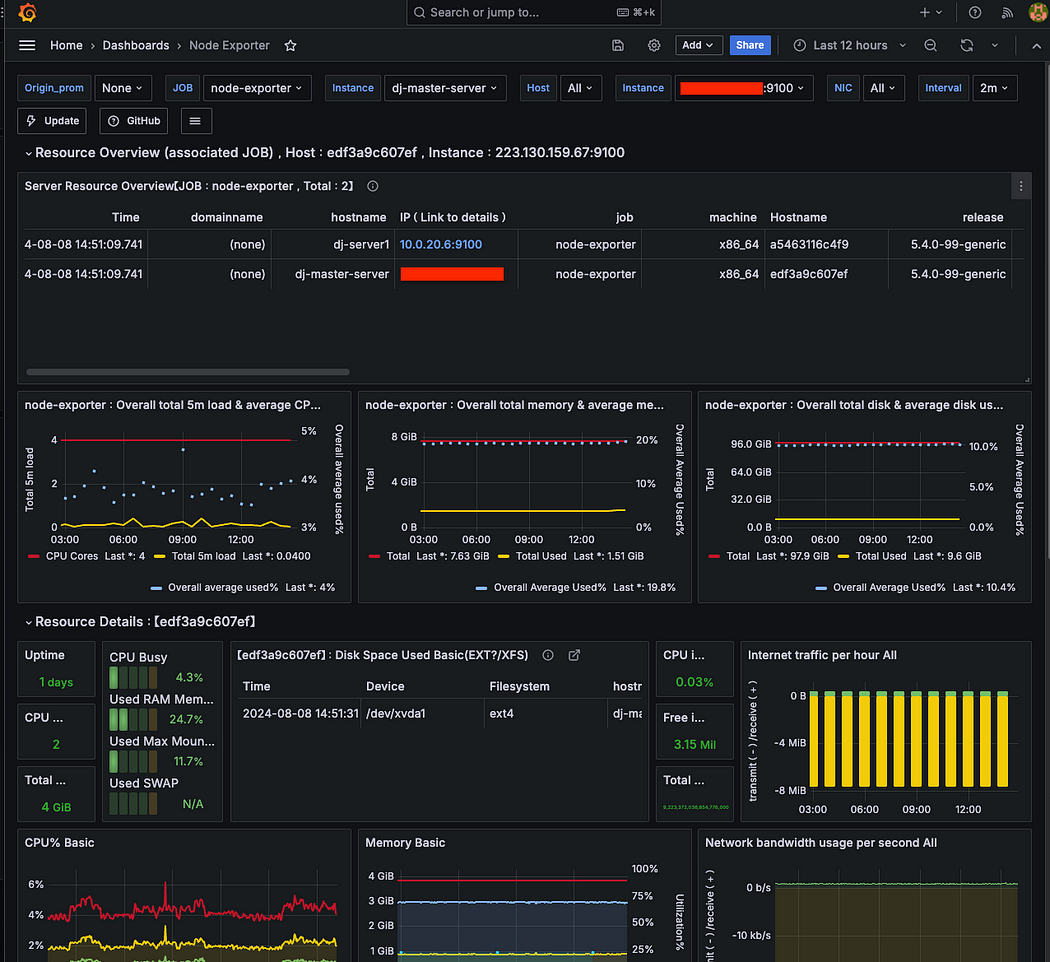
특정 서버 또는 전체 서버를 선택하여 Node 서버의 CPU, 메모리, 디스크 I/O, 파일 시스템등 다양한 시스템 리소스를 모니터링할 수 있도록 구성되어 있다. cAdvisor는 컨테이너 단위의 메트릭을, Node Exporter는 노드 단위의 시스템 메트릭을 제공하여, 각각의 수준에서 리소스 사용량을 쉽게 확인할 수 있다.
Grafana Json Model
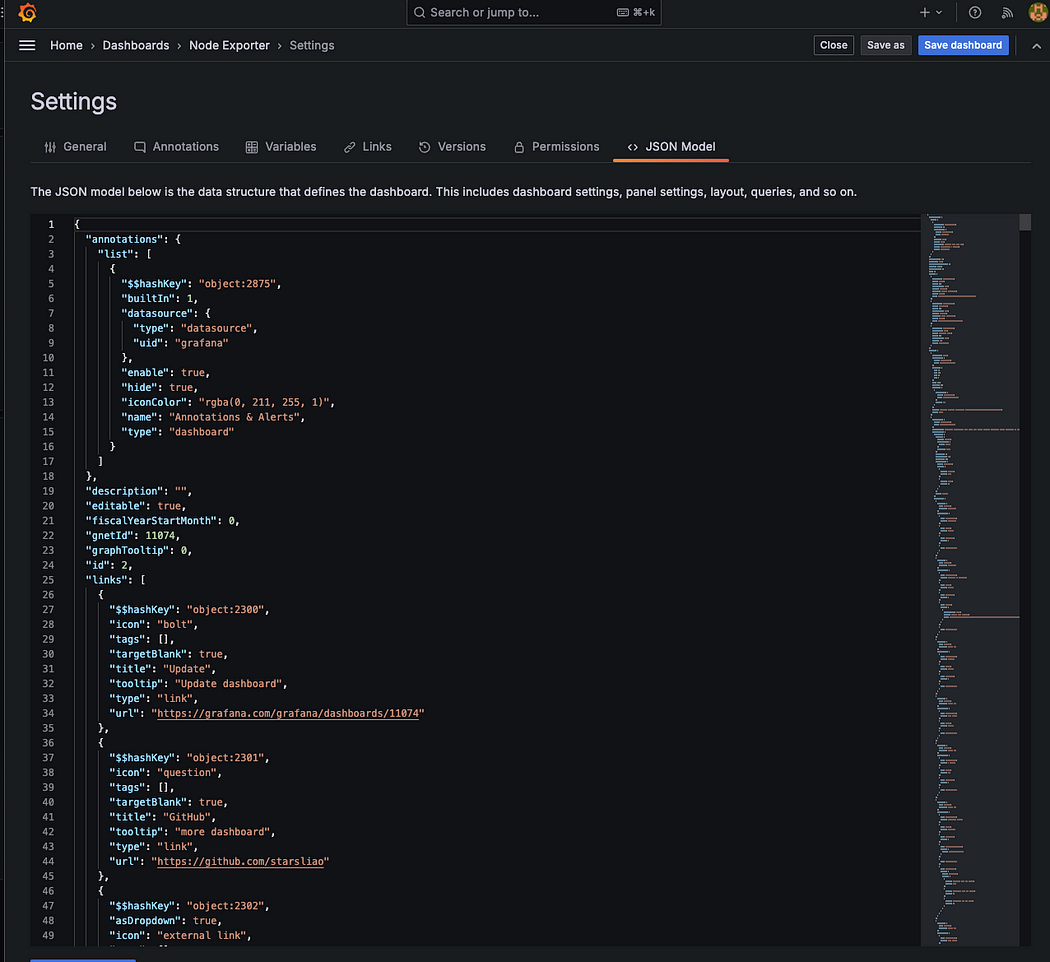
위 이미지처럼 Grafana 설정의 JSON 모델을 통해 대시보드를 원하는 형태로 자유롭게 커스터마이징할 수 있다. 현재 적용된 대시보드는 컨테이너 실행 시 설정해두었던 node-dashboard.json 파일을 기반으로 구성된 것이다.
Grafana Variables
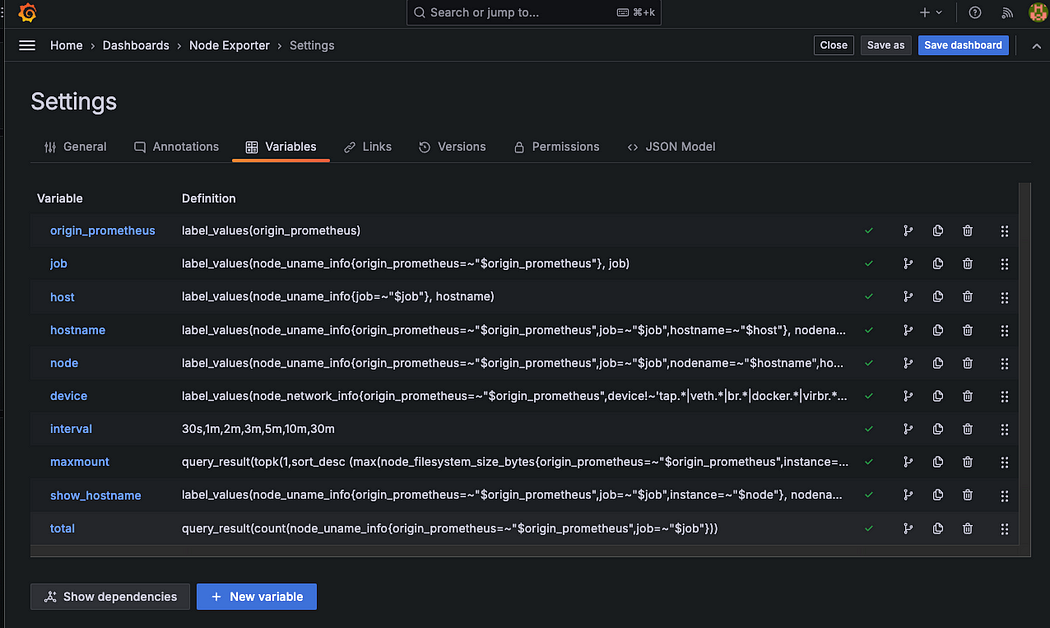
Grafana에서는 변수(Variables) 기능을 제공한다. 예를 들어, Prometheus 설정 파일(prometheus.yml)에 정의된 라벨 중 hostname과 같은 값을 PromQL을 이용해 변수로 선언하면, Grafana 대시보드에서 해당 호스트를 선택하여 원하는 서버의 메트릭만 필터링해 볼 수 있다.

Grafana 대시보드의 GUI에서도 해당 변수를 기반으로 쿼리를 작성할 수 있다.
Log Dashboard
Dashboard 클릭

Dashboard 설정에서 New Dashboard를 선택한 뒤 Add visualization을 클릭하면 대시보드를 직접 구성할 수 있다. 또는 Import a dashboard 기능을 사용하면 다른 사용자가 만든 JSON 형식의 대시보드를 그대로 불러와 사용할 수도 있다.
DataSorce 선택
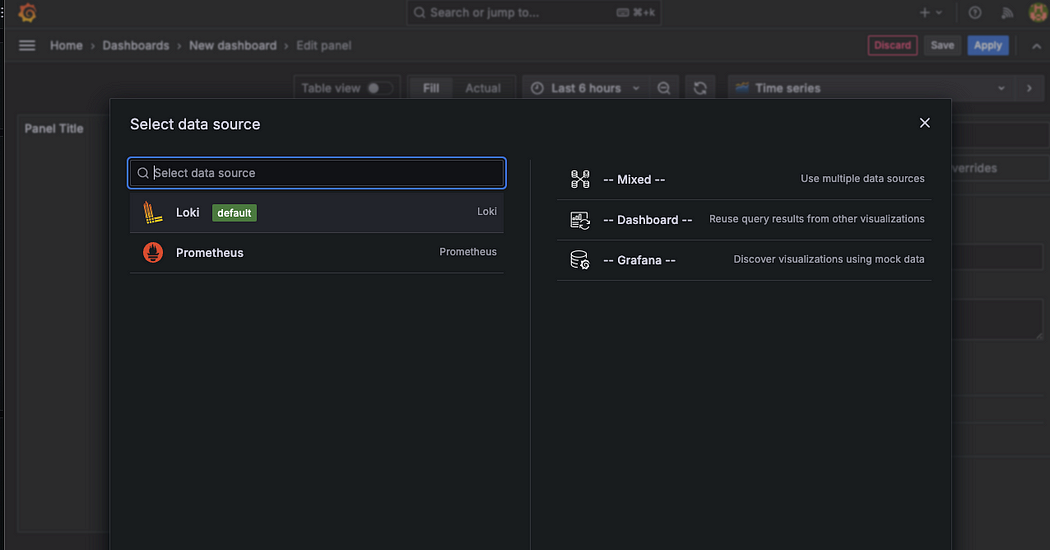
대시보드를 생성하거나 쿼리를 작성하려면 데이터를 가져올 데이터 소스가 필요하므로, 데이터 소스 설정에서 Loki를 선택해 연결해주어야 한다
Loki 컨테이너 로그 확인
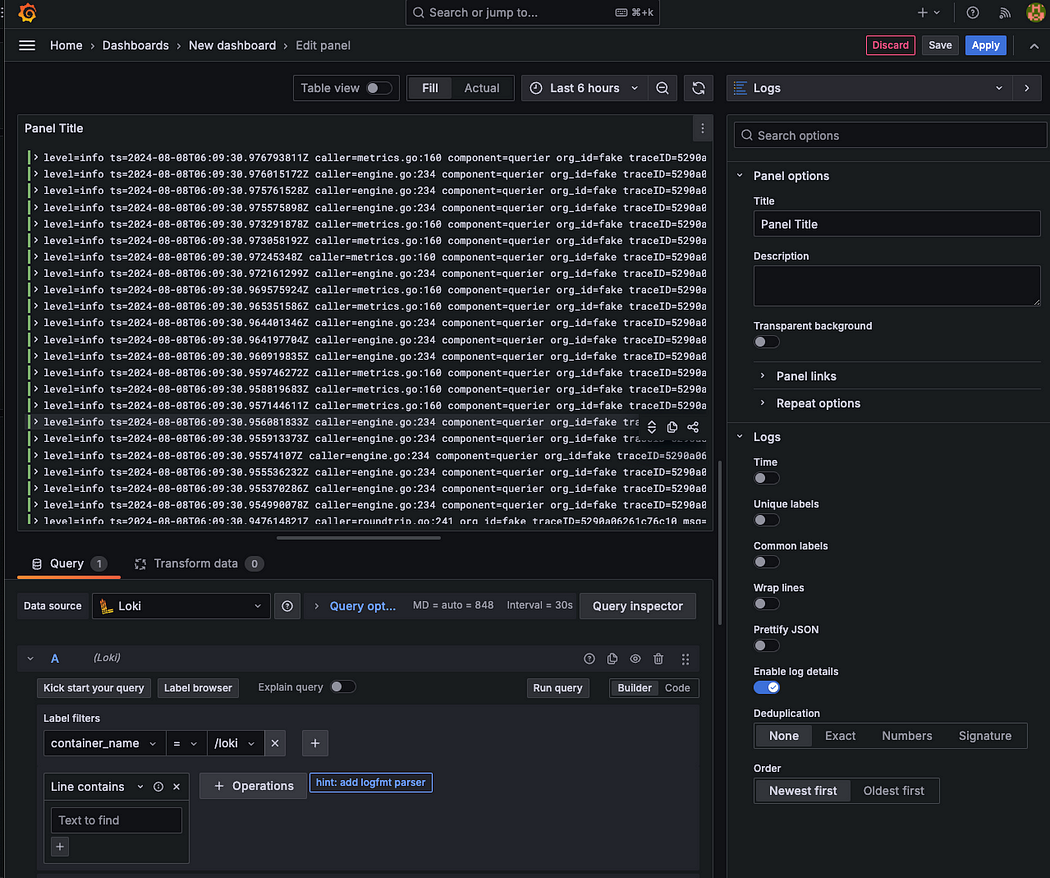
간단하게 Loki 컨테이너의 로그를 확인해보겠다. 라벨에서 loki를 선택하면 해당 컨테이너의 로그가 출력된다. 이후 필터링 기능을 활용해 원하는 로그만 추출할 수 있다.
Error 필터링
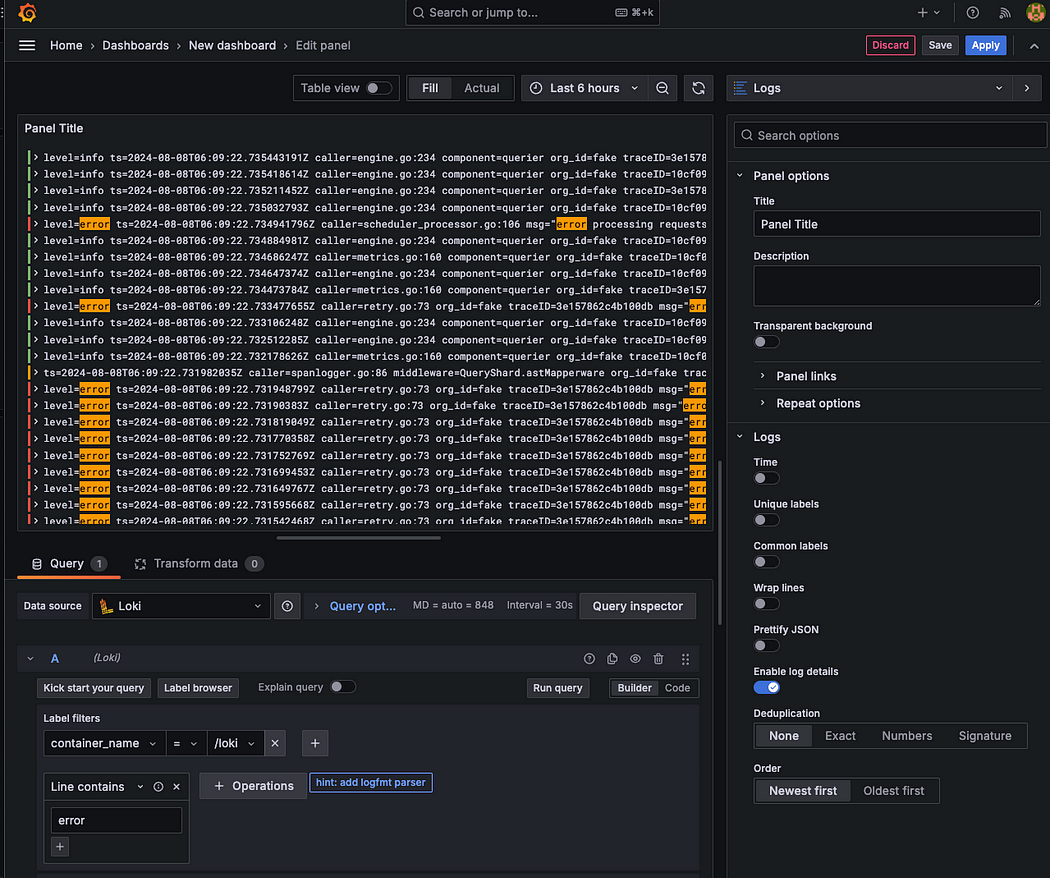
error 로그만 조회할 수 있도록 필터를 설정한 뒤, Apply를 클릭하면 해당 조건에 맞는 로그만 출력되는 대시보드를 만들 수 있다.
개선할점
- 현재는 일반 VM 환경을 기반으로 모니터링 시스템을 구축하였지만, 최근에는 대부분의 시스템이 Kubernetes 기반 컨테이너 환경에서 운영되고 있기 때문에, 추후에는 동일한 모니터링 스택을 Kubernetes 환경에서도 직접 구축해볼 계획이다.
- 현재 Loki는 로컬 파일 시스템에 로그 데이터를 저장하고 있는데, 이로 인해 디스크 용량 부족 문제가 발생하였다. 로그 저장이 지속될수록 용량 문제가 반복될 수 있으므로, 로컬 디스크대신 S3와 같은 오브젝트 스토리지를 저장소로 사용하도록 변경할 예정이다.
- Prometheus는 기본적으로 로컬 스토리지를 사용하며, S3 등 외부 스토리지 연동이 불가능하고 고가용성(HA) 구성에도 제약이 있다. 이 문제를 해결하기 위해, 향후에는 Thanos 또는 Mimir와 같은 오픈소스 컴포넌트를 도입하여 장기 보관 및 HA 구성이 가능한 Prometheus 기반 모니터링 시스템으로 확장해보고자 한다.