

HA 클러스터 설정 옵션
- etcd 노드가 제어 평면 노드와 동일한 위치에 배치된 스택된 제어 평면 노드 사용
- 외부 etcd 노드의 경우 etcd가 제어 평면과 별도의 노드에서 실행
공식문서: https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/ha-topology/
스택된 etcd 토폴로지
스택형 HA 클러스터에서 각 제어 평면 노드는 자체 etcd 멤버 인스턴스를 실행한다. 이 etcd 멤버는 해당 노드의 kube-apiserver와만 직접 통신하며, 다른 노드의 etcd 멤버들과 데이터 동기화를 수행한다. 이를 통해 Kubernetes 클러스터는 분산 데이터 저장소 구조를 유지하며 데이터 복제와 무결성을 보장한다.
kube-apiserver는 로드 밸런서를 통해 워커 노드에 노출되며, 이 로드 밸런서는 요청을 여러 제어 평면 노드로 분산시켜 고가용성을 유지한다. 한마디로 컨트롤플레인을 여러개 두어 각각의 apiserver와 etcd를 두면서 고가용성을 유지하는 것이다.
고가용성 설정 권장 사항
스택형 HA 클러스터는 최소 3개의 제어 평면 노드로 구성하는 것을 권장한다. 이는 etcd의 과반수 투표 방식을 통해 데이터 일관성을 유지하기 위함이다. 다음과 같이 모든 워커노드가 컨트롤플레인과 통신하기 위해서는 join할때 로드밸런서의 엔드포인트를 사용해야 한다.
첫 번째 제어 평면 노드 생성
kubeadm init --control-plane-endpoint "LOAD_BALANCER_IP:6443" --upload-certs추가 제어 평면 노드 연결
kubeadm join LOAD_BALANCER_IP:6443 --token <TOKEN> \
--discovery-token-ca-cert-hash sha256:<HASH> \
--control-plane
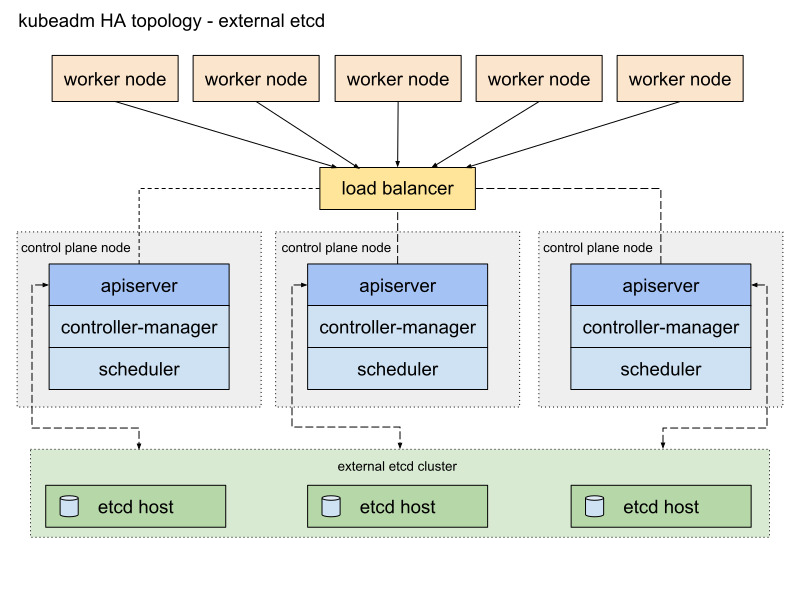
외부 etcd 토폴로지
외부 etcd HA 클러스터에서는 각 컨트롤 플레인과 외부 etcd 멤버와 통신하며 Kubernetes API 서버(kube-apiserver)는 로드 밸런서를 통해 노출된다. 이는 스택형 HA 클러스터와 유사하지만 etcd 멤버가 제어 평면 노드와 분리되어 장애가 발생해도 제어 평면과 etcd 간 독립적인 장애 복구가 가능하다. 예를들어 컨트롤플레인이 다운되어도 etcd는 계속 동작하며 데이터가 안전하게 보존된다. 그리고 이 etcd를 바탕으로 새 컨트롤 플레인을 추가하여 복구할 수 있다. 다만, 추가적인 리소스가 필요하고 운영 관리가 복잡할 수 있으므로 인프라 환경과 요구 사항을 고려해 선택하는 것이 좋다. 하지만 대규모 프로덕션 환경에서는 안정성과 고가용성을 위해서 이 솔류션이 적합하다.
'kubernetes' 카테고리의 다른 글
| [Kubernetes] Multi-Pod Scheduler (0) | 2024.12.12 |
|---|---|
| [kubernetes] Version Upgrade (0) | 2024.12.11 |
| [Kubernetes] 인증(RBAC) (0) | 2024.12.11 |
| [kubernetes] Pod AutoScaling(HPA) (0) | 2024.12.10 |
| [Kubernetes] StatefulSet (0) | 2024.12.10 |